【www.myl5520.com--网络散文】
支持向量机非线性回归通用MATLAB源码
篇一:支持向量机,sas
支持向量机非线性回归通用MATLAB源码
支持向量机和BP神经网络都可以用来做非线性回归拟合,但它们的原理是不相同的,支持向量机基于结构风险最小化理论,普遍认为其泛化能力要比神经网络的强。大量仿真证实,支持向量机的泛化能力强于BP网络,而且能避免神经网络的固有缺陷——训练结果不稳定。本源码可以用于线性回归、非线性回归、非线性函数拟合、数据建模、预测、分类等多种应用场合,GreenSim团队推荐您使用。
function [Alpha1,Alpha2,Alpha,Flag,B]=SVMNR(X,Y,Epsilon,C,TKF,Para1,Para2)
%%
% SVMNR.m
% Support Vector Machine for Nonlinear Regression
% All rights reserved
%%
% 支持向量机非线性回归通用程序
% GreenSim团队原创作品,转载请注明
% GreenSim团队长期从事算法设计、代写程序等业务
% 欢迎访问GreenSim——算法仿真团队→
% 程序功能:
% 使用支持向量机进行非线性回归,得到非线性函数y=f(x1,x2,…,xn)的支持向量解析式, % 求解二次规划时调用了优化工具箱的quadprog函数。本函数在程序入口处对数据进行了 % [-1,1]的归一化处理,所以计算得到的回归解析式的系数是针对归一化数据的,仿真测 % 试需使用与本函数配套的Regression函数。
% 主要参考文献:
% 朱国强,刘士荣等.支持向量机及其在函数逼近中的应用.华东理工大学学报
% 输入参数列表
% X 输入样本原始数据,n×l的矩阵,n为变量个数,l为样本个数
% Y 输出样本原始数据,1×l的矩阵,l为样本个数
% Epsilon ε不敏感损失函数的参数,Epsilon越大,支持向量越少
% C 惩罚系数,C过大或过小,泛化能力变差
% TKF Type of Kernel Function 核函数类型
% TKF=1 线性核函数,注意:使用线性核函数,将进行支持向量机的线性回归
% TKF=2 多项式核函数
% TKF=3 径向基核函数
% TKF=4 指数核函数
% TKF=5 Sigmoid核函数
% TKF=任意其它值,自定义核函数
% Para1 核函数中的第一个参数
% Para2 核函数中的第二个参数
% 注:关于核函数参数的定义请见Regression.m和SVMNR.m内部的定义
% 输出参数列表
% Alpha1 α系数
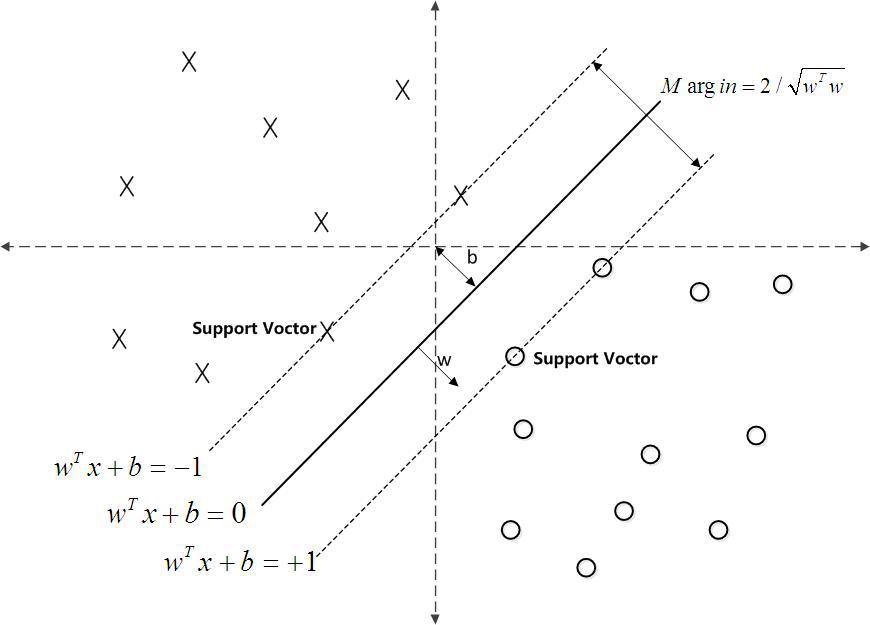
% Alpha2 α*系数
% Alpha 支持向量的加权系数(α-α*)向量支持向量机,sas。
% Flag 1×l标记,0对应非支持向量,1对应边界支持向量,2对应标准支持向量 % B 回归方程中的常数项
%--------------------------------------------------------------------------
%%
%-----------------------数据归一化处理--------------------------------------
nntwarn off
X=premnmx(X);
Y=premnmx(Y);
%%
%%
%-----------------------核函数参数初始化------------------------------------
switch TKF
case 1
%线性核函数 K=sum(x.*y)
%没有需要定义的参数
case 2
%多项式核函数 K=(sum(x.*y)+c)^p
c=Para1;%c=0.1;
p=Para2;%p=2;支持向量机,sas。
case 3
%径向基核函数 K=exp(-(norm(x-y))^2/(2*sigma^2))
sigma=Para1;%sigma=6;
case 4
%指数核函数 K=exp(-norm(x-y)/(2*sigma^2))
sigma=Para1;%sigma=3;
case 5
%Sigmoid核函数 K=1/(1+exp(-v*sum(x.*y)+c))
v=Para1;%v=0.5;
c=Para2;%c=0;
otherwise
%自定义核函数,需由用户自行在函数内部修改,注意要同时修改好几处!
%暂时定义为 K=exp(-(sum((x-y).^2)/(2*sigma^2)))支持向量机,sas。
sigma=Para1;%sigma=8;
end
%%
%%
%-----------------------构造K矩阵-------------------------------------------
l=size(X,2);
K=zeros(l,l);%K矩阵初始化
for i=1:l
for j=1:l
x=X(:,i);
y=X(:,j);
switch TKF%根据核函数的类型,使用相应的核函数构造K矩阵
case 1
K(i,j)=sum(x.*y);
case 2
K(i,j)=(sum(x.*y)+c)^p;
case 3
K(i,j)=exp(-(norm(x-y))^2/(2*sigma^2));
case 4
K(i,j)=exp(-norm(x-y)/(2*sigma^2));
case 5
K(i,j)=1/(1+exp(-v*sum(x.*y)+c));
otherwise
K(i,j)=exp(-(sum((x-y).^2)/(2*sigma^2)));
end
end
end
%%
%%
%------------构造二次规划模型的参数H,Ft,Aeq,Beq,lb,ub------------------------
%支持向量机非线性回归,回归函数的系数,要通过求解一个二次规划模型得以确定 Ft=[Epsilon*ones(1,l)-Y,Epsilon*ones(1,l)+Y];
Aeq=[ones(1,l),-ones(1,l)];
Beq=0;
ub=C*ones(2*l,1);
%%
%%
%--------------调用优化工具箱quadprog函数求解二次规划------------------------
OPT=optimset;
OPT.LargeScale='off';
OPT.Display='off';
%%
%%
%------------------------整理输出回归方程的系数------------------------------
Alpha1=(Gamma(1:l,1))';
Alpha2=(Gamma((l+1):end,1))';
Alpha=Alpha1-Alpha2;
Flag=2*ones(1,l);
%%
%%
%---------------------------支持向量的分类----------------------------------
Err=0.000000000001;
for i=1:l
AA=Alpha1(i);
BB=Alpha2(i);
if (abs(AA-0)<=Err)&&(abs(BB-0)<=Err)
Flag(i)=0;%非支持向量
end
if (AA>Err)&&(AA Flag(i)=2;%标准支持向量
end
if (abs(AA-0)<=Err)&&(BB>Err)&&(BB Flag(i)=2;%标准支持向量
end
if (abs(AA-C)<=Err)&&(abs(BB-0)<=Err)
Flag(i)=1;%边界支持向量
end
if (abs(AA-0)<=Err)&&(abs(BB-C)<=Err)
Flag(i)=1;%边界支持向量
end
end
%%
%%
%--------------------计算回归方程中的常数项B---------------------------------
B=0;
counter=0;
for i=1:l
AA=Alpha1(i);
BB=Alpha2(i);
if (AA>Err)&&(AA %计算支持向量加权值
SUM=0;
for j=1:l
if Flag(j)>0
switch TKF
case 1
SUM=SUM+Alpha(j)*sum(X(:,j).*X(:,i));
case 2
SUM=SUM+Alpha(j)*(sum(X(:,j).*X(:,i))+c)^p;
case 3
SUM=SUM+Alpha(j)*exp(-(norm(X(:,j)-X(:,i)))^2/(2*sigma^2));
case 4
SUM=SUM+Alpha(j)*exp(-norm(X(:,j)-X(:,i))/(2*sigma^2));
case 5
SUM=SUM+Alpha(j)*1/(1+exp(-v*sum(X(:,j).*X(:,i))+c));
otherwise
SUM=SUM+Alpha(j)*exp(-(sum((X(:,j)-X(:,i)).^2)/(2*sigma^2)));
end
end
end
b=Y(i)-SUM-Epsilon;
B=B+b;
counter=counter+1;
end
if (abs(AA-0)<=Err)&&(BB>Err)&&(BB SUM=0;
for j=1:l
if Flag(j)>0
switch TKF
case 1
SUM=SUM+Alpha(j)*sum(X(:,j).*X(:,i));
case 2
SUM=SUM+Alpha(j)*(sum(X(:,j).*X(:,i))+c)^p;
case 3
SUM=SUM+Alpha(j)*exp(-(norm(X(:,j)-X(:,i)))^2/(2*sigma^2));
case 4
SUM=SUM+Alpha(j)*exp(-norm(X(:,j)-X(:,i))/(2*sigma^2));
case 5
SUM=SUM+Alpha(j)*1/(1+exp(-v*sum(X(:,j).*X(:,i))+c));
otherwise
SUM=SUM+Alpha(j)*exp(-(sum((X(:,j)-X(:,i)).^2)/(2*sigma^2)));
end
end
end
b=Y(i)-SUM+Epsilon;
B=B+b;
counter=counter+1;
end
end
if counter==0
B=0;
else
B=B/counter;
end
欢迎访问GreenSim团队主页:
欢迎访问GreenSim——算法仿真团队→
function y=Regression(Alpha,Flag,B,X,Y,TKF,Para1,Para2,x)
%--------------------------------------------------------------------------
数据挖掘之遗传规划
篇二:支持向量机,sas
遗传规划(genetic programming)和决策树(classification tree)
关于遗传规划方法,给我的资料中以剑桥大学Dempster和Jones的文章介绍的原理和方法比较全面和清晰(使用遗传规划方法的实时自适应交易系统,A real-time adaptive trading system using genetic programming) ,以下就我的理解说明这种方法的问题。
遗传规划总结出来的交易规则可以用决策树表达,它只是决策树中的一个,这个决策树和我们直接用穷举法得到的分类效果最好的决策树相比在训练数据上肯定是逊色的。(除了中国人写的论文之外,我没有搜索到一篇实证说明遗传算法在训练数据上表现更好的)
从分类思想上遗传规划的方法也是把自变量空间划分成多个长方形,它和决策树的根本思想是一致的。不同的是遗传规划是用遗传杂交的方式选择更好的规则,而决策树是用穷举的方式计算出来最好的规则。实际上对于我们的问题,穷举不费事(我的软件的分类树算法使用了一个很简单的小技巧基本解决了这个问题)。
遗传规划借鉴的遗传筛选方法是不确定性算法,需要花费长时间才可以接近最优解。对交易规则的选择只有在花费大量时间的情况下才接近最佳规则。
遗传规划选择最优规则的可行域小于或等于实际的可行域。使用论文中固定二进制长度的进化方式,例如0.3<RSI<0.7这样的规则条件就很难实现。如果不固定长度,算法要复杂得多且这个搜索花费的时间应很长。
我的想法是:它只是探索中的方法,到实用的阶段可能还需要突破性改进才行。
遗传规划在SAS EM里面没有出现,支持向量机只有在2013年以后的SAS EM里面作为试验性方法(非正规,且非客户端)出现。我作为学术方面不入流(写算法是一流,哈)的人一会就能发现这些方法的问题,这些方法成熟十几年了都不让出现在正规软件里面,你可以想象顶级专家们对这两种方法的看法。